import asyncio
import os
import random
import logging
import hashlib
from typing import List, Dict
import aiosqlite
from telethon import TelegramClient
from telethon.tl.types import MessageMediaDocument, DocumentAttributeVideo, Message
from telethon.errors import (
FloodWaitError,
SecurityError,
FileReferenceExpiredError,
rpcerrorlist
)
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
# ==================== 📁 文件夹初始化 ====================
DB_FOLDER = "database"
SESSION_FOLDER = "session"
for folder in [DB_FOLDER, SESSION_FOLDER]:
if not os.path.exists(folder):
os.makedirs(folder)
# ==================== 🛠️ 配置读取帮助函数 ====================
def get_env_float(key, default=0.0):
val = os.getenv(key, "")
if not val: return default
try:
return float(val)
except ValueError:
print(f"⚠️ 配置错误: {key} 必须是数字,当前为 '{val}',已重置为 {default}")
return default
def get_env_int(key, default=0):
val = os.getenv(key, "")
if not val: return default
try:
return int(val)
except ValueError:
return default
# ==================== ⚙️ 基础配置 ====================
API_ID = get_env_int("API_ID")
API_HASH = os.getenv("API_HASH")
PHONE_NUMBER = os.getenv("PHONE_NUMBER")
MIN_SIZE_MB = get_env_float("MIN_SIZE_MB", 0)
MAX_SIZE_MB = get_env_float("MAX_SIZE_MB", 0)
MIN_DURATION = get_env_int("MIN_DURATION", 0)
MAX_DURATION = get_env_int("MAX_DURATION", 0)
STOP_AFTER_DUPLICATES = 100
MAX_SCAN_COUNT = 22000
MIN_INTERVAL = 2
MAX_INTERVAL = 5
ALBUM_WAIT_TIME = 3.0
# ==================== 📋 任务清单 ====================
TASK_CONFIG = [
# ADULT INDUSTRY 到 town1
{
"sources": [-1001245945922],
"target": -xxx,
"limit": 300
},
]
# ==================== 日志初始化 ====================
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(message)s",
datefmt="%H:%M:%S"
)
logger = logging.getLogger("AutoBot")
# --- 修改:Session 路径移动到 session 文件夹 ---
session_path = os.path.join(SESSION_FOLDER, "user_session")
client = TelegramClient(session_path, API_ID, API_HASH)
# 全局状态变量
forward_queue = None
pending_albums = {}
album_timers = {}
db = None
# ==================== 🗄️ 数据库类 ====================
class AsyncDB:
def __init__(self, path):
self.path = path
self.conn = None
self.lock = asyncio.Lock()
async def connect(self):
self.conn = await aiosqlite.connect(self.path)
await self.conn.execute("CREATE TABLE IF NOT EXISTS videos (video_key TEXT PRIMARY KEY)")
await self.conn.commit()
async def close(self):
if self.conn: await self.conn.close()
async def seen(self, key):
async with self.lock:
async with self.conn.execute("SELECT 1 FROM videos WHERE video_key=?", (key,)) as cursor:
return await cursor.fetchone() is not None
async def mark(self, key):
async with self.lock:
await self.conn.execute("INSERT OR IGNORE INTO videos (video_key) VALUES (?)", (key,))
await self.conn.commit()
# ==================== 🛠️ 核心工具函数 ====================
def get_unique_key(msg: Message) -> str:
return f"{msg.chat_id}_{msg.media.document.id}"
def generate_safe_filename(sources: List[int], target: int) -> str:
"""修改:确保文件名包含文件夹路径"""
sources_str = "_".join([str(abs(s)) for s in sources])
target_str = str(abs(target))
if len(sources_str) > 50:
hash_object = hashlib.md5(sources_str.encode())
short_hash = hash_object.hexdigest()[:8]
preview = "_".join([str(abs(s)) for s in sources[:2]])
fname = f"{preview}_etc_{short_hash}_to_{target_str}.db"
else:
fname = f"{sources_str}to{target_str}.db"
# 拼接数据库文件夹路径
return os.path.join(DB_FOLDER, fname)
def is_video(msg: Message) -> bool:
if not msg.media or not isinstance(msg.media, MessageMediaDocument):
return False
doc = msg.media.document
if not doc.mime_type.startswith("video"):
return False
video_attr = next((a for a in doc.attributes if isinstance(a, DocumentAttributeVideo)), None)
if getattr(video_attr, "round_message", False):
return False
size_mb = doc.size / (1024.0 * 1024.0)
if MIN_SIZE_MB > 0 and size_mb < MIN_SIZE_MB: return False
if MAX_SIZE_MB > 0 and size_mb > MAX_SIZE_MB: return False
if video_attr:
duration = video_attr.duration
if MIN_DURATION > 0 and duration < MIN_DURATION: return False
if MAX_DURATION > 0 and duration > MAX_DURATION: return False
return True
# ==================== 🔄 异步逻辑 ====================
async def process_album_later(grouped_id):
try:
await asyncio.sleep(ALBUM_WAIT_TIME)
if grouped_id in pending_albums:
messages = pending_albums.pop(grouped_id)
album_timers.pop(grouped_id, None)
if messages:
messages.sort(key=lambda x: x.id)
await forward_queue.put(messages)
except asyncio.CancelledError:
pass
async def queue_message(message: Message):
if message.grouped_id:
gid = message.grouped_id
if gid not in pending_albums: pending_albums[gid] = []
pending_albums[gid].append(message)
if gid in album_timers: album_timers[gid].cancel()
album_timers[gid] = asyncio.create_task(process_album_later(gid))
else:
await forward_queue.put([message])
async def worker(target_channel_id):
processed_count = 0
while True:
try:
batch = await forward_queue.get()
if batch is None:
forward_queue.task_done()
break
files = [m.media for m in batch]
caption = batch[0].text or ""
try:
await client.send_file(target_channel_id, files, caption=caption)
processed_count += len(batch)
logger.info(f"✅ 发送成功 | 本次: {len(batch)} | 总计: {processed_count}")
for m in batch:
await db.mark(get_unique_key(m))
await asyncio.sleep(random.uniform(MIN_INTERVAL, MAX_INTERVAL))
except FloodWaitError as e:
logger.warning(f"⏳ 触发流控: 暂停 {e.seconds} 秒")
await asyncio.sleep(e.seconds + 2)
except FileReferenceExpiredError:
logger.error("❌ 文件引用过期,跳过")
except Exception as e:
logger.error(f"❌ 发送异常: {e}")
forward_queue.task_done()
except Exception as e:
logger.error(f"Worker Error: {e}")
async def scanner(source_channels, forward_limit):
all_collected_videos = []
for ch in source_channels:
channel_collected = 0
logger.info(f"🔍 正在扫描: {ch} (目标: {forward_limit})")
consecutive_duplicates = 0
scanned_count = 0
async for msg in client.iter_messages(ch, limit=MAX_SCAN_COUNT):
scanned_count += 1
if scanned_count % 200 == 0:
print(f"\r ...扫描深度: {scanned_count} 条", end="")
if not is_video(msg): continue
if await db.seen(get_unique_key(msg)):
consecutive_duplicates += 1
if consecutive_duplicates >= STOP_AFTER_DUPLICATES:
print(f"\n🛑 [频道 {ch}] 连续 {STOP_AFTER_DUPLICATES} 条重复,停止扫描。")
break
else:
consecutive_duplicates = 0
all_collected_videos.append(msg)
channel_collected += 1
print(f"\r📦 [频道 {ch}] 命中: {channel_collected}/{forward_limit}", end="")
if channel_collected >= forward_limit:
print(f"\n✅ [频道 {ch}] 额度已满")
break
print("")
if all_collected_videos:
logger.info(f"📊 找到 {len(all_collected_videos)} 个新视频。排序入队...")
all_collected_videos.sort(key=lambda x: x.date)
for msg in all_collected_videos:
await queue_message(msg)
if pending_albums:
logger.info("⏳ 等待相册分组...")
while pending_albums or album_timers:
finished = [k for k, t in album_timers.items() if t.done()]
for k in finished: del album_timers[k]
if not album_timers and not pending_albums: break
await asyncio.sleep(0.5)
else:
logger.info("⚠️ 没有发现任何新视频。")
await forward_queue.put(None)
async def run_single_task(task):
global db, forward_queue, pending_albums, album_timers
sources = task['sources']
target = task['target']
limit = task.get('limit', 200)
# 这里 generate_safe_filename 已经包含 database 路径
full_db_path = generate_safe_filename(sources, target)
logger.info(f"\n🚀 >>> 启动任务: {os.path.basename(full_db_path)} <<<")
# 彻底重置状态
forward_queue = asyncio.Queue()
pending_albums = {}
album_timers = {}
db = AsyncDB(full_db_path)
await db.connect()
worker_task = asyncio.create_task(worker(target))
try:
await scanner(sources, limit)
await forward_queue.join()
except Exception as e:
logger.error(f"❌ 任务运行异常: {e}")
finally:
if not worker_task.done():
worker_task.cancel()
await db.close()
logger.info(f"🏁 >>> 任务结束: {os.path.basename(full_db_path)} <<<\n")
# ==================== 🚀 主程序入口 ====================
async def main():
print("="*50)
print("🎥 Auto-Forwarder Pro (Task Sequencer)")
print(f"📉 最小视频限制: {MIN_SIZE_MB} MB")
print(f"📈 最大视频限制: {MAX_SIZE_MB if MAX_SIZE_MB > 0 else '不限'} MB")
print("="*50)
if not TASK_CONFIG:
logger.error("❌ TASK_CONFIG 为空,请在代码中配置任务列表!")
return
await client.start(PHONE_NUMBER)
try:
total_tasks = len(TASK_CONFIG)
for index, task in enumerate(TASK_CONFIG):
await run_single_task(task)
if index < total_tasks - 1:
wait_sec = 10
logger.info(f"⏳ 任务 [{index + 1}/{total_tasks}] 已完成。")
logger.info(f"⏳ 冷却中... {wait_sec} 秒后执行下一个任务...")
await asyncio.sleep(wait_sec)
else:
logger.info("🎉 所有任务已按顺序执行完毕!")
except KeyboardInterrupt:
print("\n👋 用户手动停止程序")
except Exception as e:
logger.error(f"🔥 系统致命错误: {e}")
finally:
await client.disconnect()
logger.info("🔌 已安全退出并断开连接")
if __name__ == "__main__":
asyncio.run(main())月度归档: 2026 年 1 月
ClawCloudRunSSL
vless://82351ae8-64d4-4b87-8adb-06775f040873@wk.bablo.eu.cc:443?encryption=none&security=tls&sni=wk.bablo.eu.cc&fp=chrome&insecure=0&allowInsecure=0&type=ws&host=wk.bablo.eu.cc&path=%2F#edgetq103
vless://f19aa64c-0de7-4475-9776-ba2f306b4b46@wk.titt.eu.cc:443?encryption=none&security=tls&sni=wk.titt.eu.cc&fp=chrome&insecure=0&allowInsecure=0&type=ws&host=wk.titt.eu.cc&path=%2F#edgetownzzr
vless://bddc0e40-b38e-4cf7-b59b-e7bfd1a53b3d@wk.an.ccwu.cc:443?encryption=none&security=tls&sni=wk.an.ccwu.cc&fp=chrome&insecure=0&allowInsecure=0&type=ws&host=wk.an.ccwu.cc&path=%2F#edgetown7850
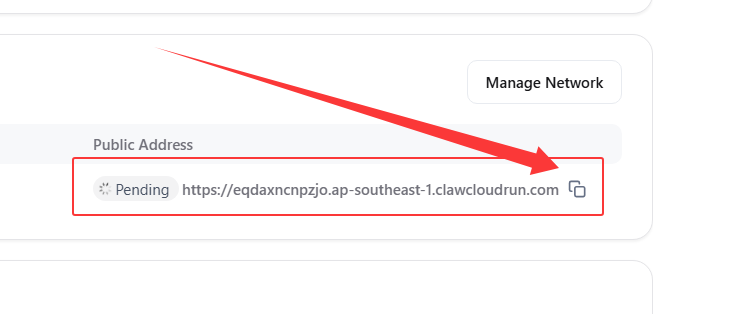
近期小伙伴部署爪云容器出现SSL证书一直提示
Pending的问题,长时间等待或更换工作区也无法解决。
所以这篇教程就来了,我们可以通过使用 Cloudflare 或 EdgeOne 来解决SSL证书问题,顺便给你的爪云容器套上CDN进行加速。🔧 配置 CDN
⚡ EdgeOne CDN
- 优点:低延迟,回源规则不设限制,支持多级域名。
- 缺点:
- 不支持免费域名,需要付费域名。
- 超长时间连接限速500Kbps,只适用于小流量项目。
🚀 点击展开 部署图文教程
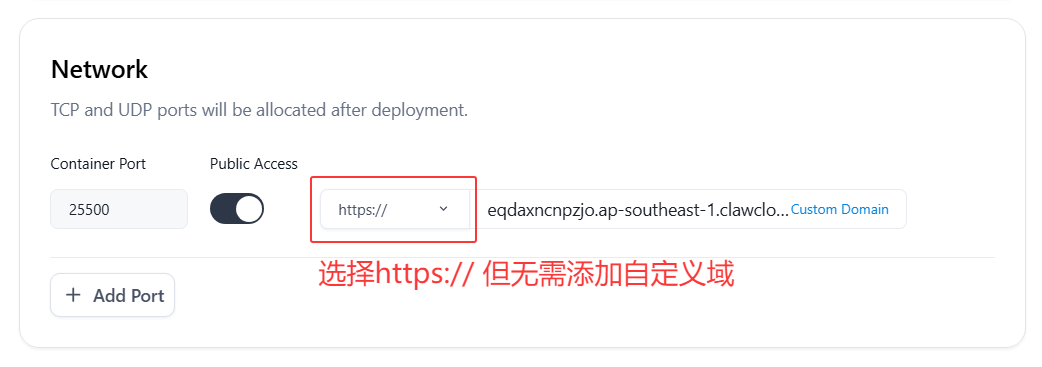
1️⃣ 记录爪云容器的域名
- 确认协议选择
https://,返回右上角点击Update更新部署。- 记录容器域名的部分,不包含
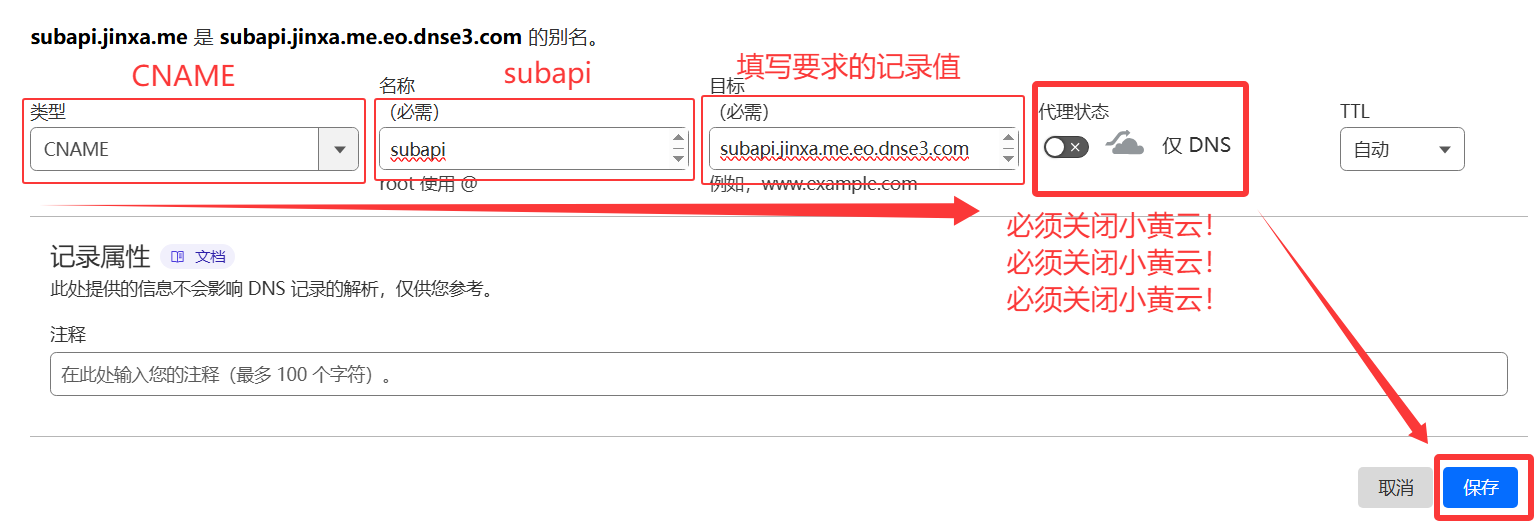
https://,例如eqdaxncnpzjo.ap-southeast-1.clawcloudrun.com2️⃣ 前往 EdgeOne 添加一个
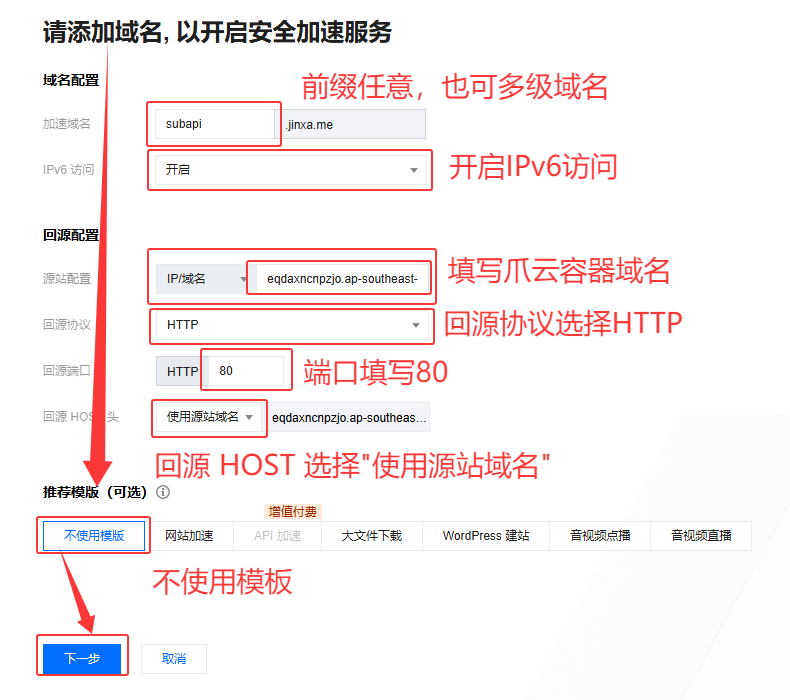
CNAME 接入域名
- 域名配置
- 加速域名:
subapi(前缀随意填写,也可填写多级域名)- IPv6 访问:
开启- 回源配置
- 源站配置:
IP/域名>eqdaxncnpzjo.ap-southeast-1.clawcloudrun.com(填写爪云容器的域名)- 回源协议:
HTTP- 回源端口:
80- 回源 HOST 头 :
使用源站域名- 推荐模板
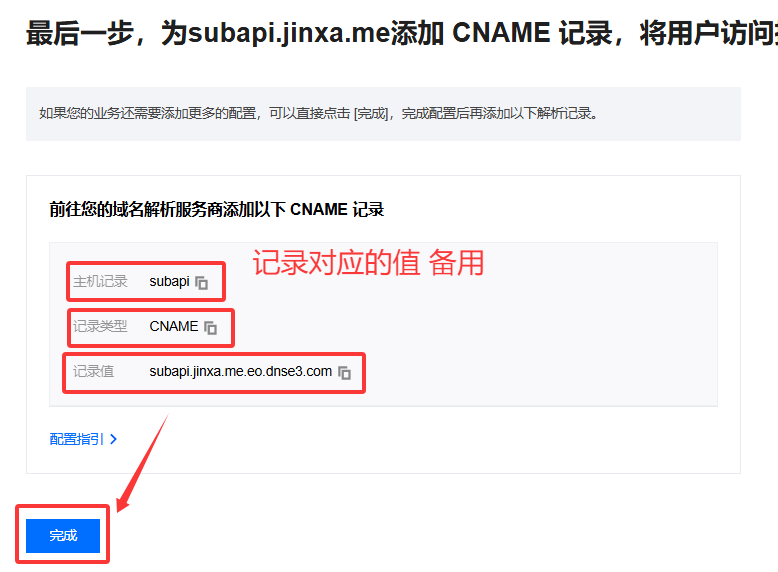
3️⃣ 记录对应的值
4️⃣ 前往域名服务商添加 CNAME 记录。
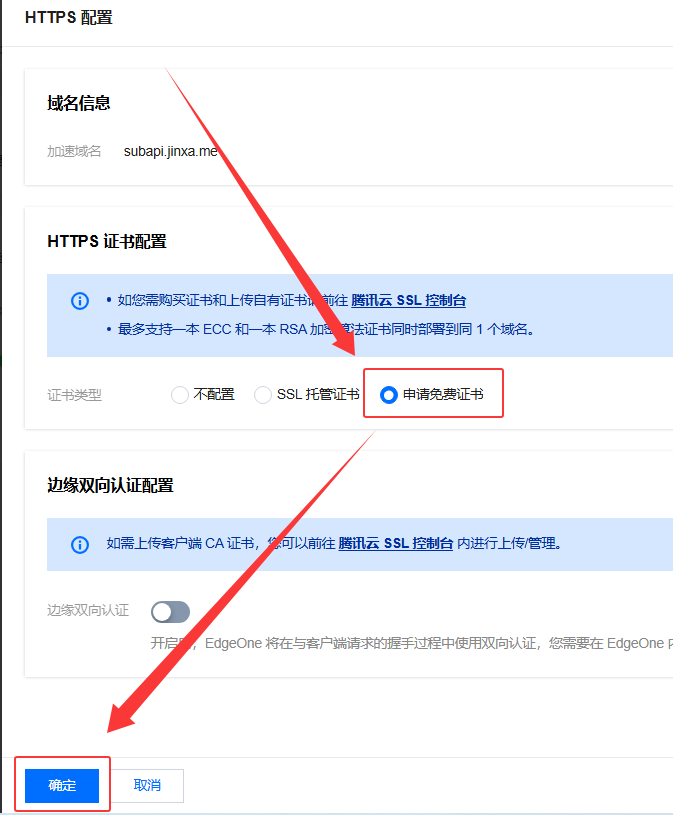
5️⃣ 等待生效后配置SSL证书
6️⃣ 完成!访问自定义域
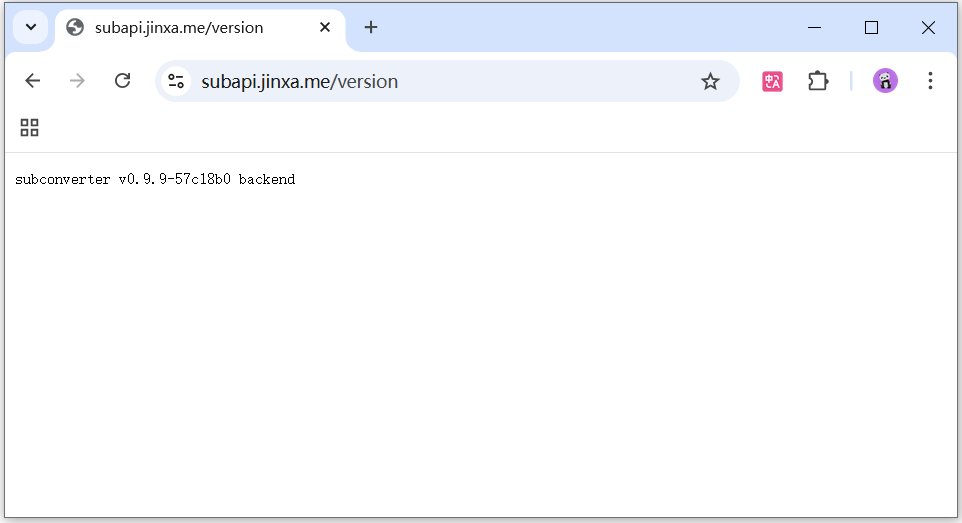
等待几分钟,成功申请免费证书后,访问 例如
https://subapi.jinxa.me/version即可访问到爪云容器。
☁️ Cloudflare CDN
- 优点:支持免费域名(除了双向解析的域名),例如
dpdns.org、us.kg等等。- 缺点:
- 占用TCP端口额度
- 配置过于复杂,需要添加
更改端口(Origin Rules)和配置规则(Configuration Rules),免费用户只能添加10条规则。- 只能使用次级域名,例如
example.dpdns.org,更多的次级层域名不会自动添加SSL证书。🚀 点击展开 部署图文教程
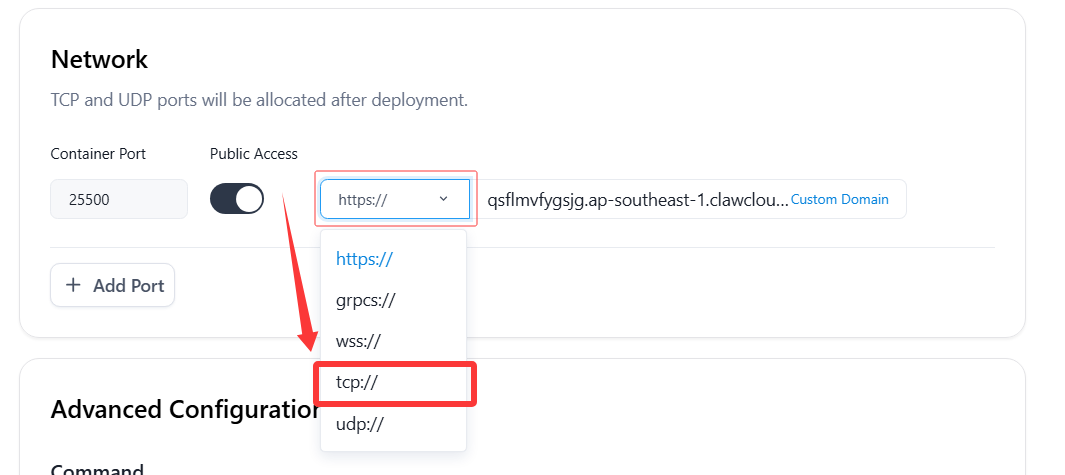
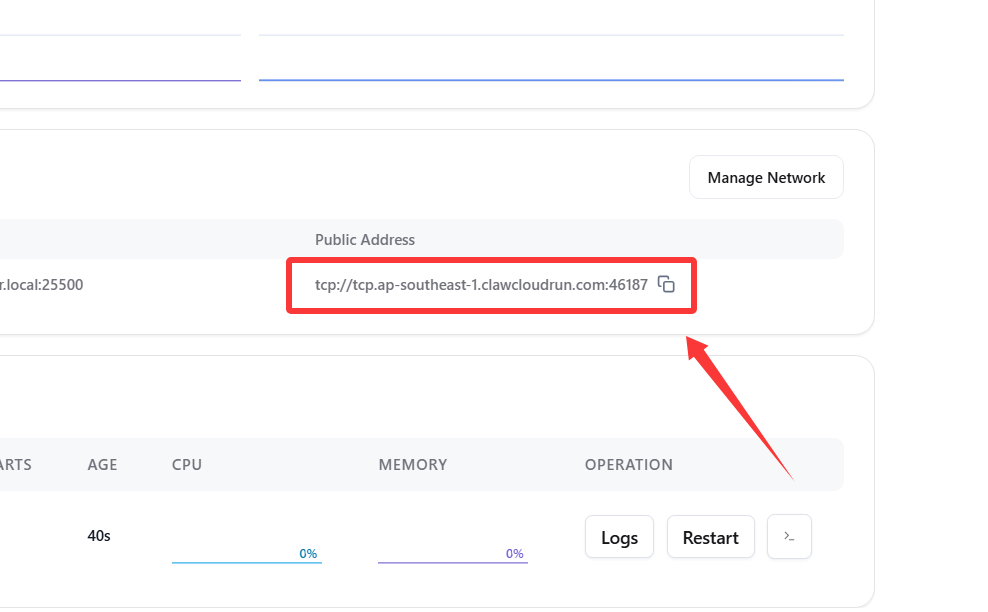
1️⃣ 切换服务为TCP模式
- 将需要套CDN的端口服务从
https://改为tcp://后,返回右上角点击Update更新部署。- 记录下分配的域名端口备用,例如 域名
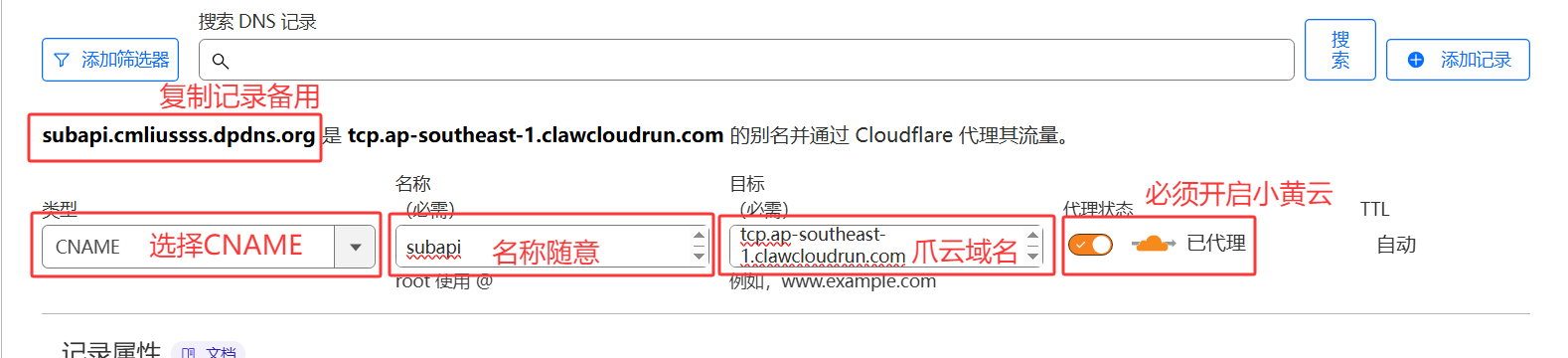
tcp.ap-southeast-1.clawcloudrun.com端口46187。2️⃣ 前往 Cloudflare 添加一个
CNAME记录,前缀随意(但是不能是多级域名,不能出现
.),值必须填写爪云分配的域名,例如tcp.ap-southeast-1.clawcloudrun.com,并记录即将使用的自定义域 例如subapi.cmliussss.dpdns.org。3️⃣ 添加
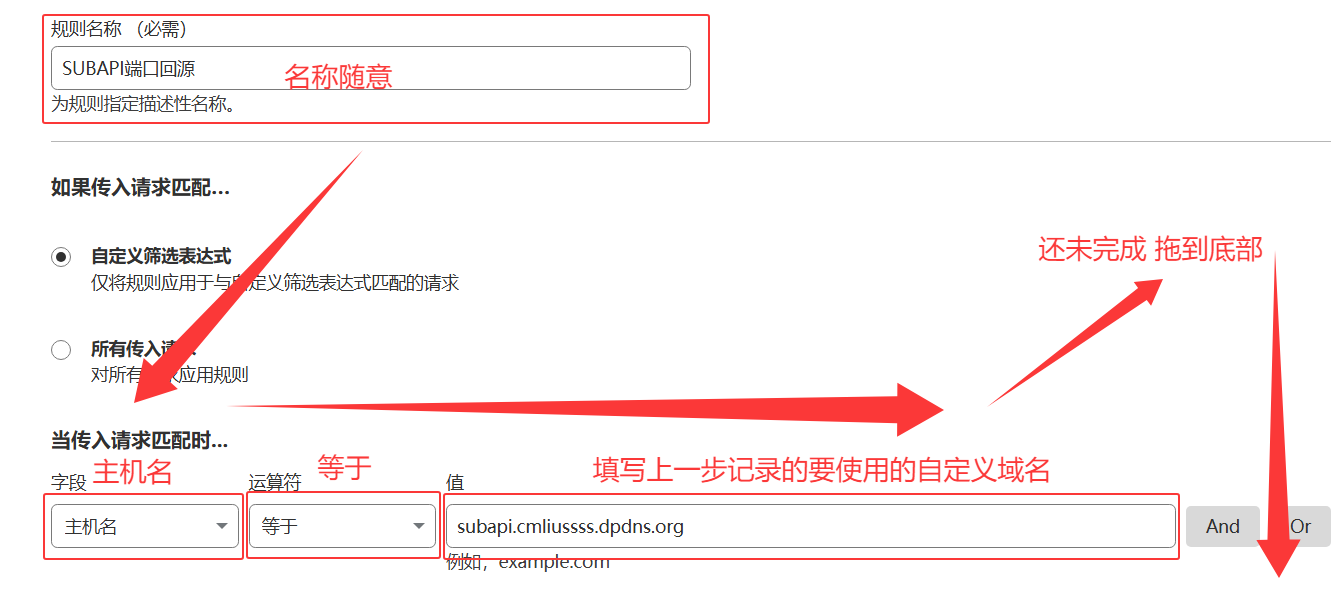
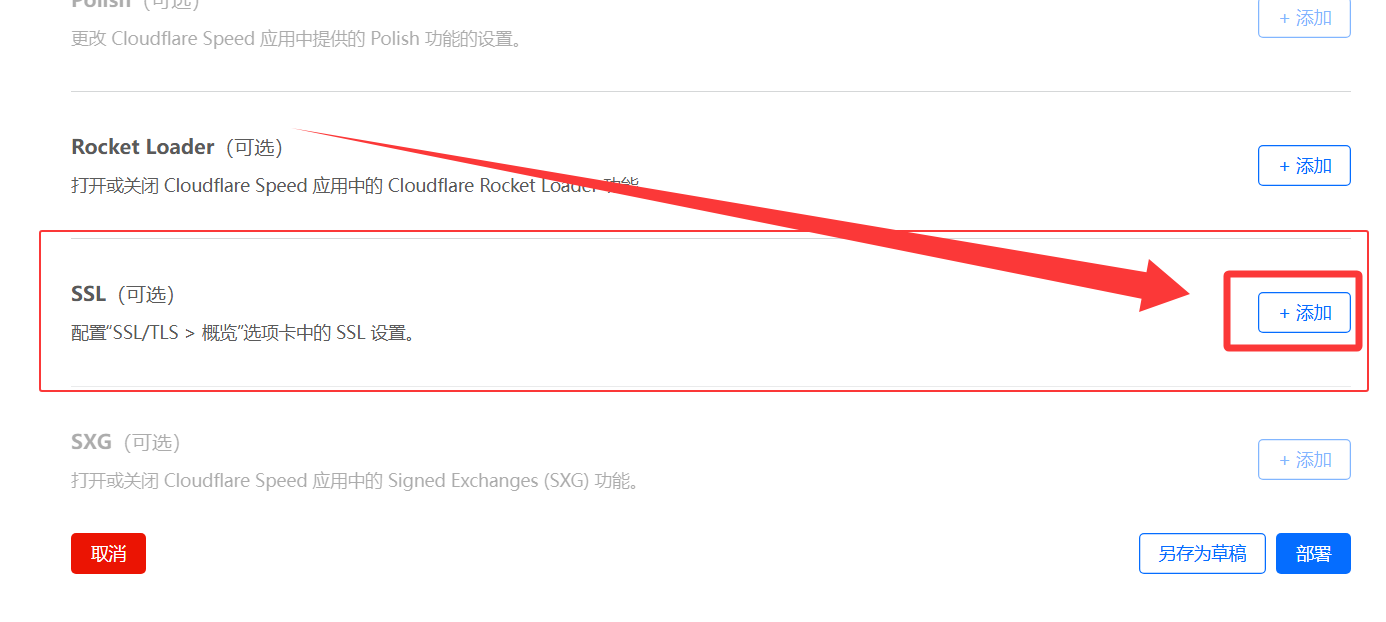
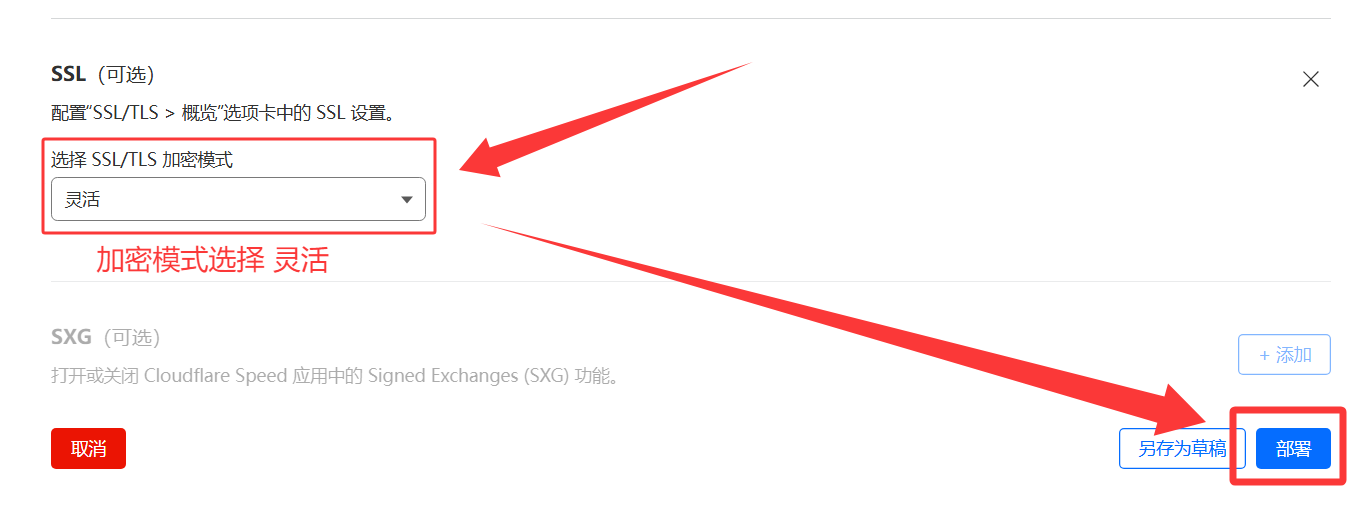
源服务器规则4️⃣ 添加
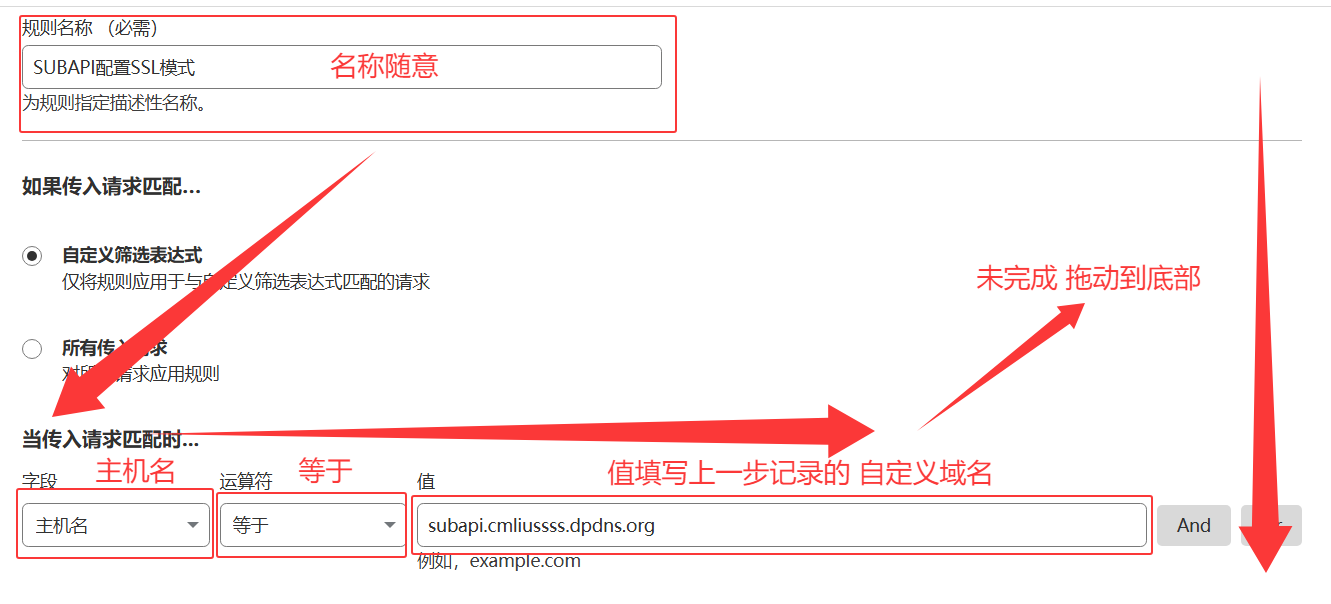
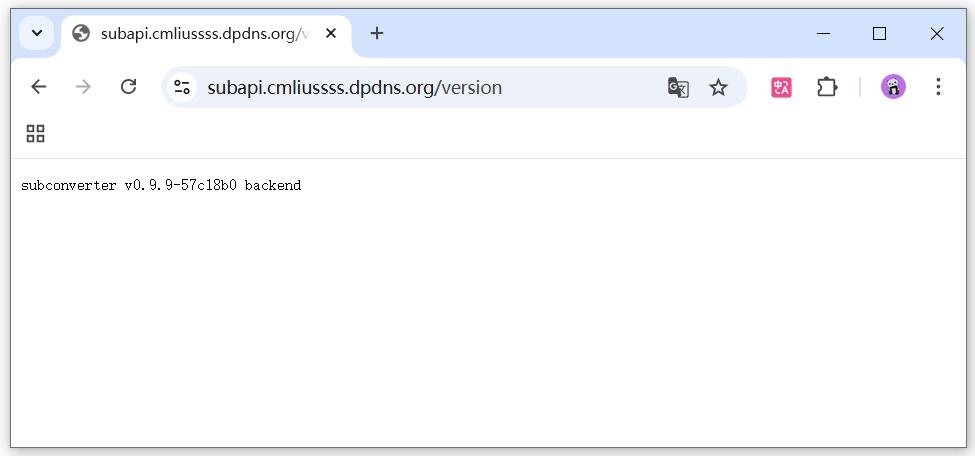
配置规则5️⃣ 完成!访问自定义域
等待几分钟,访问 例如
https://subapi.cmliussss.dpdns.org/version即可访问到爪云容器。
新人Youtuber,需要您的支持,请务必帮我点赞、关注、打开小铃铛,十分感谢!!!



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
remove_duplicates
import asyncio
import os
import sys
from telethon import TelegramClient, errors
from telethon.tl.types import MessageMediaDocument, DocumentAttributeFilename
from dotenv import load_dotenv
# ================== 1. 读取配置 频道视频去重==================
load_dotenv()
try:
api_id = int(os.getenv("API_ID"))
api_hash = os.getenv("API_HASH")
PHONE_NUMBER = os.getenv("PHONE_NUMBER")
TWO_STEP_PASSWORD = os.getenv("TWO_STEP_PASSWORD") or None
# --- 修复:自动判断频道 ID 是数字还是用户名 ---
raw_target = os.getenv("TARGET_CHANNEL")
try:
# 如果是数字(如 -100xxx),转换为整数
TARGET_CHANNEL = int(raw_target)
except (ValueError, TypeError):
# 如果不是数字(如 @username),保持字符串
TARGET_CHANNEL = raw_target
# 扫描限制:设置为想要扫描的【视频数量】
scan_env = os.getenv("SCAN_LIMIT", "21000")
TARGET_VIDEO_COUNT = int(scan_env)
except Exception as e:
print(f"❌ 配置错误: {e}")
sys.exit(1)
client = TelegramClient("session/user_session", api_id, api_hash)
# ================== 2. 工具函数 ==================
def get_video_info(message):
"""
解析视频信息
返回: (is_video, file_id, file_name)
"""
if not message.media or not isinstance(message.media, MessageMediaDocument):
return False, None, None
doc = message.media.document
# 判定是否为视频 mime 类型
if not (doc.mime_type and doc.mime_type.startswith("video/")):
return False, None, None
# 获取文件名(仅用于显示,不用于判重)
file_name = "未知文件名"
for attr in doc.attributes:
if isinstance(attr, DocumentAttributeFilename):
file_name = attr.file_name
break
# Telethon document.id 是该文件在 TG 系统内的唯一标识
return True, doc.id, file_name
# ================== 3. 主逻辑 ==================
async def main():
print("🔐 正在登录 Telegram...")
# 自动处理登录,如果是第一次运行,控制台会要求输入验证码
await client.start(phone=PHONE_NUMBER, password=TWO_STEP_PASSWORD)
print("✅ 登录成功")
try:
# 获取频道实体对象
target = await client.get_entity(TARGET_CHANNEL)
target_name = getattr(target, "title", TARGET_CHANNEL)
except Exception as e:
print(f"❌ 无法获取频道信息: {TARGET_CHANNEL}")
print(f" 原因: {e}")
print(" 提示: 请确保你已经加入了该频道,且 ID 填写正确(ID必须是整数,不带引号)。")
return
# 显示当前任务模式
mode_str = "无限 (直到扫描完所有历史)" if TARGET_VIDEO_COUNT == 0 else f"最近 {TARGET_VIDEO_COUNT} 个视频"
print(f"\n📺 目标频道:{target_name}")
print(f"🎯 扫描目标:{mode_str}")
print(f"⚙️ 判重策略:保留【最新】发布的视频,删除旧的重复项")
print("-" * 40)
seen_keys = set() # 记录已出现的视频 ID
duplicates = [] # 存储待删除的消息 [(msg_id, file_name), ...]
scanned_msgs = 0 # 扫描过的消息总数(含文字/图片)
found_videos = 0 # 找到的视频数
print("⏳ 正在扫描消息 (顺序:从新 -> 旧)...")
# limit=None 表示如果不手动 break,就一直扫描下去
async for msg in client.iter_messages(target, limit=None):
scanned_msgs += 1
is_vid, file_id, file_name = get_video_info(msg)
if not is_vid:
continue
# 找到一个视频
found_videos += 1
# 核心判重逻辑
if file_id in seen_keys:
# 已经在 seen_keys 里,说明之前扫描到了(即更新的消息里有这个视频)
# 所以当前这条较旧的消息是重复的
duplicates.append((msg.id, file_name))
else:
seen_keys.add(file_id)
# 打印进度条
if found_videos % 20 == 0:
print(f" 已检索 {found_videos} 个视频 (总扫描消息 {scanned_msgs} 条)...")
# 达到数量限制,退出循环
if TARGET_VIDEO_COUNT != 0 and found_videos >= TARGET_VIDEO_COUNT:
print(f"✅ 已达到设定的 {TARGET_VIDEO_COUNT} 个视频目标,停止扫描。")
break
print("-" * 40)
print("📊 扫描结果统计")
print(f" 总扫描消息数:{scanned_msgs}")
print(f" 检索视频总数:{found_videos}")
print(f" 发现重复视频:{len(duplicates)}")
if not duplicates:
print("✅ 没有发现需要删除的重复视频")
return
print(f"\n⚠️ 即将删除 {len(duplicates)} 条【旧的重复】视频")
# 等待用户确认
confirm = input("❓ 确认删除?(输入 y 确认,其他键取消): ").strip().lower()
if confirm != "y":
print("🚫 已取消操作")
return
print("🗑️ 开始执行删除任务...")
# 提取所有要删除的消息 ID
delete_ids = [d[0] for d in duplicates]
batch_size = 50 # 每次删除 50 条,防止请求过大
for i in range(0, len(delete_ids), batch_size):
batch = delete_ids[i:i + batch_size]
try:
await client.delete_messages(target, batch)
print(f" 已删除 {min(i + batch_size, len(delete_ids))}/{len(delete_ids)}")
# 适当延时,保护账号安全
await asyncio.sleep(1.5)
except errors.FloodWaitError as e:
print(f"⏳ 触发 Telegram 流控 (FloodWait),需等待 {e.seconds} 秒...")
await asyncio.sleep(e.seconds + 2)
except errors.MessageIdInvalidError:
print(f"⚠️ 某些消息可能已经被删除,跳过该批次")
except Exception as e:
print(f"❌ 删除出错: {e}")
print(f"\n✅ 清理完成!")
# ================== 4. 程序入口 ==================
if __name__ == "__main__":
# 使用 with 语法自动管理连接和断开
with client:
client.loop.run_until_complete(main())